1 Introduction to Data Heterogeneity
Data heterogeneity in federated learning refers to different users holding data with different distributions (i.e. non-I.I.D., data non independent identical distribution). The common data heterogeneity in experiments in existing federated learning papers is mainly the following two categories:
- Label Skew: Different users hold different distribution of tags, for example, in the federal handwritten digit classification task, some users only hold a sample of the number 1;
- Feature Skew: different users hold different distributions of features, such as different users holding different styles of handwritten digital images 1;
In addition to these two isomerities, there are Concept Drift (i.e. different X corresponds to the same Y) and Concept Shift (i.e. the same X corresponds to different Y), which are less conducted in experiments by previous works. Different types of heterogeneity generally accompany each other. For example, in the above label heterogeneous example, users with local labels with only the number 1 also hold images with only the number 1 feature.
2 Customization on Data Heterogeneity
General Process of FLGo
In FLGo, the process of generating and running each federation task can be simply thought of as the following 4 steps:
- Load: Load the original dataset
- Partition: Divide the original dataset (customizing here)
- Save: Save the division information
- Running-time Reload: Load raw data and partitioning information, and recover the divided dataset.
For the vast majority of datasets, custom data heterogeneity depends on how the datasets are divided. We let class Partitioner be responsible for the partition step, and its instance method __call__(data: Any)->List[List[int]] will partition the indices of samples in the original datasets.
import flgo.benchmark.partition as fbp
from typing import *
class MyPartitioner(fbp.BasicPartitioner):
def __call__(self, data:Any):
r"""The partitioned results should be of type List[List[int]],
where each list element saves the partitioning information for a client.
"""
local_datas = []
return local_datas
Example 1: Imbalanced IID Partitioner on MNIST
import flgo.benchmark.mnist_classification
import flgo.benchmark.partition as fbp
import numpy as np
# 1. Define the partitioner
class MyIIDPartitioner(fbp.BasicPartitioner):
def __init__(self, samples_per_client=[15000, 15000, 15000, 15000]):
self.samples_per_client = samples_per_client
self.num_clients = len(samples_per_client)
def __call__(self, data):
# 1.1 shuffle the indices of samples
d_idxs = np.random.permutation(len(data))
# 1.2 Divide all the indices into num_clients shards
local_datas = np.split(d_idxs, np.cumsum(self.samples_per_client))[:-1]
local_datas = [di.tolist() for di in local_datas]
return local_datas
# 2. Specify the Partitioner in task configuration
task_config = {
'benchmark': flgo.benchmark.mnist_classification,
'partitioner':{
'name':MyIIDPartitioner,
'para':{
'samples_per_client':[5000, 14000, 19000, 22000]
}
}
}
task = 'my_test_partitioner'
# 3. Test it now
flgo.gen_task(task_config, task)
import flgo.algorithm.fedavg as fedavg
runner = flgo.init(task, fedavg)
runner.run()
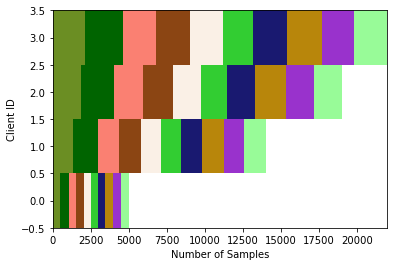
Example 2: Feature Skew Partitioner
FLGo has integrated data partitioners commonly used in existing papers, such as IID data partitioning, diversity data partitioning, Dirichlet data partitioning, etc. These partitioners can divide specific data by specifying properties that partition dependencies in the task configuration parameters task_config. For example, in the MNIST handwritten digit classification task, the pixel density of different images is different. To differ the levels of pixel densities of images held by different users, you can bind all samples to a label representing the pixel density size and then have the partitioner rely on this property to divide. For all partitioners, the parameter in the constructor index_func: X->list[Any] specifies the basis for the partition. For example:
"""
class DiversityPartitioner(BasicPartitioner):
def __init__(self, num_clients=100, diversity=1.0, index_func=lambda X:[xi[-1] for xi in X]):
self.num_clients = num_clients
self.diversity = diversity
self.index_func = index_func # 指定按照什么属性的多样性进行划分
...
class IDPartitioner(BasicPartitioner):
def __init__(self, num_clients=-1, priority='random', index_func=lambda X:X.id):
self.num_clients = int(num_clients)
self.priorty = priority
self.index_func = index_func # 指定按照什么属性为ID
...
class DirichletPartitioner(BasicPartitioner):
def __init__(self, num_clients=100, alpha=1.0, error_bar=1e-6, imbalance=0, index_func=lambda X:[xi[-1] for xi in X]):
self.num_clients = num_clients
self.alpha = alpha
self.imbalance = imbalance
self.index_func = index_func # 指定按照什么属性服从狄利克雷分布
self.error_bar = error_bar
"""
index_func receives the same input as the __call__ method of the corresponding partitioner, and the output is a list of the same length as data, where each element is of some attribute value (e.g. such as pixel density) of the corresponding sample. The following examples takes the pixel density of MNIST as an example to illustrate how to construct the desired data heterogeneity by specifying index_func function
import flgo.benchmark.mnist_classification
import flgo.benchmark.partition as fbp
import torch
# 1. Define index_func
def index_func(data):
xfeature = torch.tensor([di[0].mean() for di in data]).argsort()
group = [-1 for _ in range(len(data))]
gid = 0
# Attach each sample with a label of pixel density
num_levels = 10
for i, did in enumerate(xfeature):
if i >= (gid + 1) * len(data) / num_levels:
gid += 1
group[did] = gid
return group
# 2. Spefify the Partitioner and pass the index_func
task_config = {
'benchmark': flgo.benchmark.mnist_classification,
'partitioner':{
'name':fbp.IDPartitioner, # IDPartitioner根据每个样本所属的ID直接构造用户,每个用户对应一个ID
'para':{
'index_func': index_func
}
}
}
task = 'my_test_partitioner2'
# 3. test it now
flgo.gen_task(task_config, task)
import flgo.algorithm.fedavg as fedavg
runner = flgo.init(task, fedavg)
runner.run()