In this section, we first introduce the general paradigm of horizontal FL and then discuss the corresponding implementation in FLGo.
2.1.1 Classical Paradigm
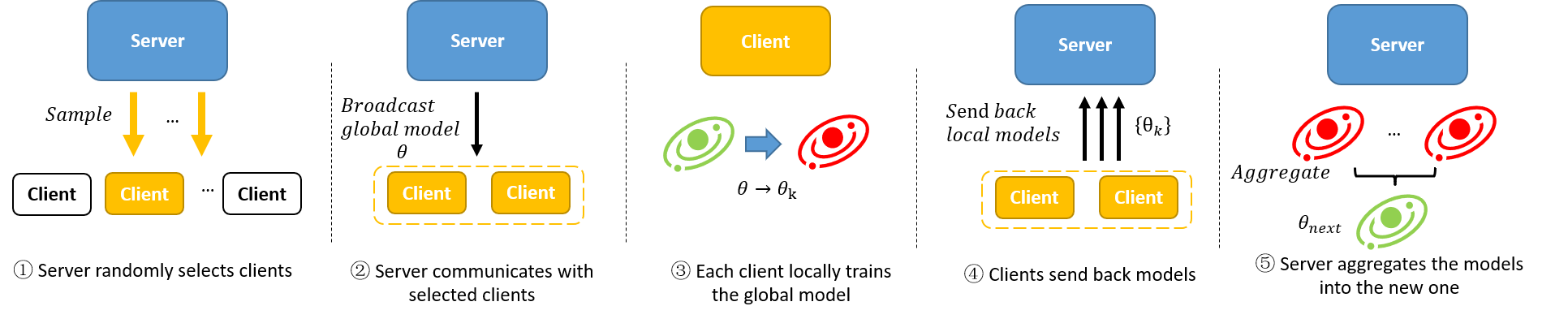
In a classical horizontal FL scene, there is a center server that coordinates clients to collaboratively train a global model iteratively. In each iteration, the server first samples a subset from all the clients. Then, the server broadcasts the global model the selected clients. After receiving the global model, the clients locally train it with local data. Finally, the clients send back the updated models to the server and the server aggregates the models into the new global model. The whole process is as shown in the figure above. Existing methods usually improve one or more of the five steps to realize various purposes like fairness and robustness.
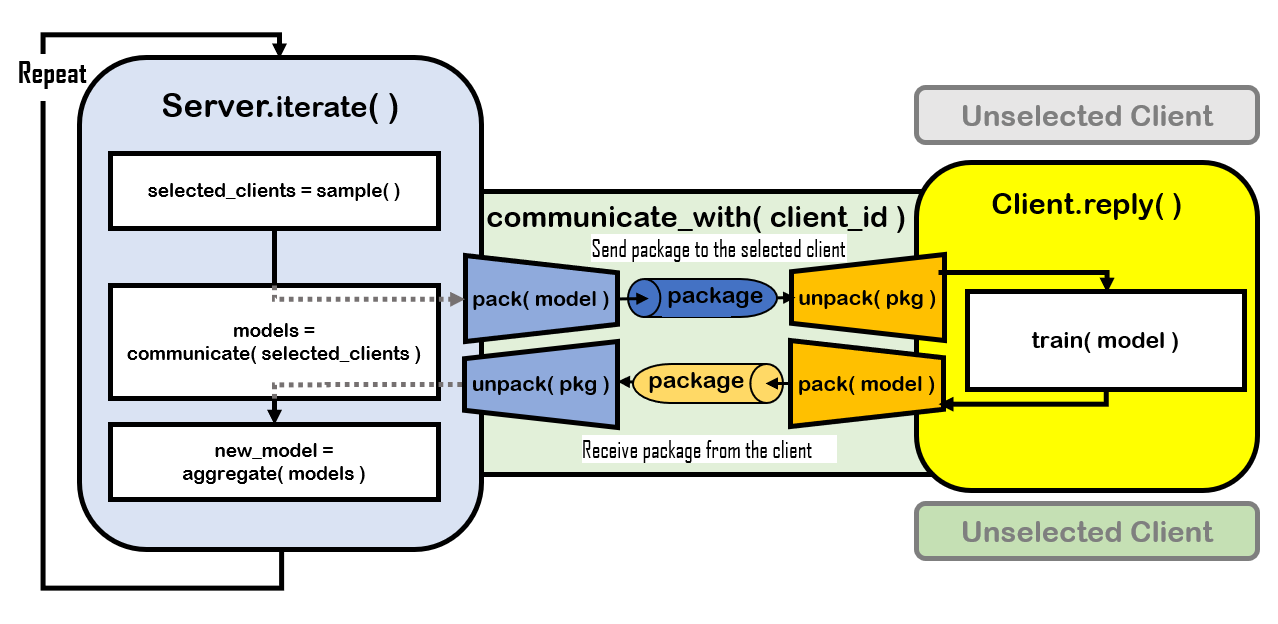
The cooresponding implementation of the FL process is shown in Figure 2. We use iterate function to model the behaviors of the server and reply function to model the behaviors of clients when being selected.
2.1.2 Details of Steps
Server's Behavior: Server.iterate
The training process starts with run method of the server, which starts iterations (i.e. communication rounds) by using a loop. In each iteration of the loop, the server will call iterate to carry out each step. A standard implementation of iterate (i.e. flgo.algorithm.fedbase.iterate) is as below:
def iterate(self):
"""
The standard iteration of each federated communication round that contains three
necessary procedure in FL: client selection, communication and model aggregation.
Returns:
False if the global model is not updated in this iteration
"""
# sample clients: Uniform sampling as default
self.selected_clients = self.sample()
# training
models = self.communicate(self.selected_clients)['model']
# aggregate: pk = ni/sum(ni) as default
self.model = self.aggregate(models)
return len(models) > 0
① Server.sample
During each iteration, the server first sample clients by calling self.sample(), which returns a list of clients' IDs. We implement three sampling strategies in our preset sampling method as below. full sampling means selecting all the clients. uniform sampling means selecting clients uniformly without replacement. md sampling means selecting clients with replacement by probabilities w.r.t. the ratio of data sizes. Improvement on sampling strategies can be adapted here by overwriting sample.
def sample(self):
r"""
Sample the clients. There are three types of sampling manners:
full sample, uniform sample without replacement, and MDSample
with replacement. Particularly, if 'available' is in self.sample_option,
the server will only sample from currently available clients.
Returns:
a list of the ids of the selected clients
Example:
```python
>>> selected_clients=self.sample()
>>> selected_clients
>>> # The selected_clients is a list of clients' ids
```
"""
all_clients = self.available_clients if 'available' in self.sample_option else [cid for cid in
range(self.num_clients)]
# full sampling with unlimited communication resources of the server
if 'full' in self.sample_option:
return all_clients
# sample clients
elif 'uniform' in self.sample_option:
# original sample proposed by fedavg
selected_clients = list(
np.random.choice(all_clients, min(self.clients_per_round, len(all_clients)), replace=False)) if len(
all_clients) > 0 else []
elif 'md' in self.sample_option:
# the default setting that is introduced by FedProx, where the clients are sampled with the probability in proportion to their local_movielens_recommendation data sizes
local_data_vols = [self.clients[cid].datavol for cid in all_clients]
total_data_vol = sum(local_data_vols)
p = np.array(local_data_vols) / total_data_vol
selected_clients = list(np.random.choice(all_clients, self.clients_per_round, replace=True, p=p)) if len(
all_clients) > 0 else []
return selected_clients
② Communication- Broadcast: Server.pack & Client.unpack
The communication process is realized by the method communicate(client_ids: list[int], mtype: str, asynchronous: bool), which contains a full ask&reply process between the server and the clients. The second step only refers to the broadcast-communication, which only describes what the server transmitting to the clients. Therefore, we use two method, Server.pack(client_id) and Client.unpack() to model the broadcast-communication process
class Server:
def pack(self, client_id, mtype=0, *args, **kwargs):
"""
Pack the necessary information for the client's local training.
Any operations of compression or encryption should be done here.
:param
client_id: the id of the client to communicate with
:return
a dict that only contains the global model as default.
"""
return {
"model" : copy.deepcopy(self.model),
}
class Client:
def unpack(self, received_pkg):
"""
Unpack the package received from the server
:param
received_pkg: a dict contains the global model as default
:return:
the unpacked information that can be rewritten
"""
# unpack the received package
return received_pkg['model']
The transmitted package should be a dict in python. The server will send a copy of the global model, and the client will unpack the package to obtain the global model as default. Any changes on the content of the down-streaming packages should be implemented here.
Clients' Behavior: Client.reply
After clients receiving the global models, the method Client.reply will automatically be triggered to model the clients' behaviors. The implementation of reply is as follows:
def reply(self, svr_pkg):
r"""
Reply a package to the server. The whole local_movielens_recommendation procedure should be defined here.
The standard form consists of three procedure: unpacking the
server_package to obtain the global model, training the global model,
and finally packing the updated model into client_package.
Args:
svr_pkg (dict): the package received from the server
Returns:
client_pkg (dict): the package to be send to the server
"""
model = self.unpack(svr_pkg)
self.train(model)
cpkg = self.pack(model)
return cpkg
③ Local Training: Client.train
The local training is made by the method Client.train, which receives a global model as the input and trains it with local data. Any modification on local training procedures should be implemented here. The default implementation is as follow:
def train(self, model):
r"""
Standard local_movielens_recommendation training procedure. Train the transmitted model with
local_movielens_recommendation training dataset.
Args:
model (FModule): the global model
"""
model.train()
optimizer = self.calculator.get_optimizer(model, lr=self.learning_rate, weight_decay=self.weight_decay,
momentum=self.momentum)
for iter in range(self.num_steps):
# get a batch of data
batch_data = self.get_batch_data()
model.zero_grad()
# calculate the loss of the model on batched dataset through task-specified calculator
loss = self.calculator.compute_loss(model, batch_data)['loss']
loss.backward()
if self.clip_grad>0:torch.nn.utils.clip_grad_norm_(parameters=model.parameters(), max_norm=self.clip_grad)
optimizer.step()
return
Particularly, we let the task-spefific calculation be transparent to the optimization algorithms. Therefore, one algorithm (e.g. FedAvg) can be adapted to different types of tasks without any changes. calculator is responsible for all the task-specific calculations.
④ Communication - Upload: Client.pack & Server.unpack
The communication of uploading models from clients is modeled by Client.pack(*args, **kwargs) and Server.unpack(packages_list), which is similar to the step ②. Different from ②, the server as the receiver needs to simultaneously handle a list of packages from different clients. We let Server.unpack return the values in the uploaded packages as a dict that shares the same keys with each client's pakcage. Modification on the content of upload-communication should be implemented in Client.pack that returns a dict as a package each time.
class Server:
def unpack(self, packages_received_from_clients):
"""
Unpack the information from the received packages. Return models and losses as default.
:param
packages_received_from_clients:
:return:
res: collections.defaultdict that contains several lists of the clients' reply
"""
if len(packages_received_from_clients)==0: return collections.defaultdict(list)
res = {pname:[] for pname in packages_received_from_clients[0]}
for cpkg in packages_received_from_clients:
for pname, pval in cpkg.items():
res[pname].append(pval)
return res
class Client:
def pack(self, model, *args, **kwargs):
"""
Packing the package to be send to the server. The operations of compression
of encryption of the package should be done here.
:param
model: the locally trained model
:return
package: a dict that contains the necessary information for the server
"""
return {
"model" : model,
}
⑤ Model Aggregation: Server.aggregate()
The server finally aggregates the received models into a new global model by the method Server.aggregate(models: list). There are four preset aggregation modes in our implementation. And using the normalized ratios of local data sizes (i.e. FedAvg) is set the default aggregatino option.
def aggregate(self, models: list, *args, **kwargs):
"""
Aggregate the locally improved models.
:param
models: a list of local models
:return
the averaged result
pk = nk/n where n=self.data_vol
K = |S_t|
N = |S|
-------------------------------------------------------------------------------------------------------------------------
weighted_scale |uniform (default) |weighted_com (original fedavg) |other
==========================================================================================================================
N/K * Σpk * model_k |1/K * Σmodel_k |(1-Σpk) * w_old + Σpk * model_k |Σ(pk/Σpk) * model_k
"""
if len(models) == 0: return self.model
local_data_vols = [c.datavol for c in self.clients]
total_data_vol = sum(local_data_vols)
if self.aggregation_option == 'weighted_scale':
p = [1.0 * local_data_vols[cid] /total_data_vol for cid in self.received_clients]
K = len(models)
N = self.num_clients
return fmodule._model_sum([model_k * pk for model_k, pk in zip(models, p)]) * N / K
elif self.aggregation_option == 'uniform':
return fmodule._model_average(models)
elif self.aggregation_option == 'weighted_com':
p = [1.0 * local_data_vols[cid] / total_data_vol for cid in self.received_clients]
w = fmodule._model_sum([model_k * pk for model_k, pk in zip(models, p)])
return (1.0-sum(p))*self.model + w
else:
p = [1.0 * local_data_vols[cid] / total_data_vol for cid in self.received_clients]
sump = sum(p)
p = [pk/sump for pk in p]
return fmodule._model_sum([model_k * pk for model_k, pk in zip(models, p)])
We will show how to modify each steps to realize different algorithms by the following sections.